骡子快跑收不收费?输出长度参数又是啥?一次讲清楚
在骡子快跑的使用中,收费方式请以官方最新公告为准,而关于输出长度,中文环境下,平均一个 token 对应 1.3~1.6 个汉字,因此设置时需预留一定缓冲;不同模式下的截断规则也不同。此外,你可以用自然语言隐式调控长度,也可以通过反复“测试”输出并反向统计实际 token 数,来推算出合理的参数。
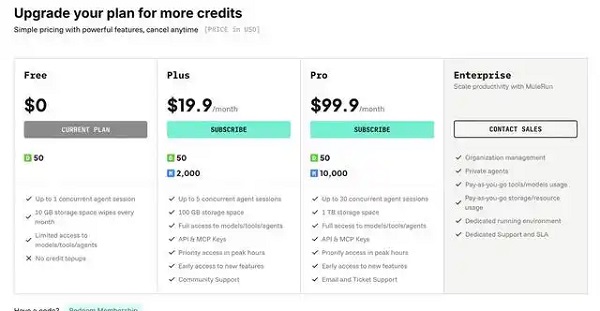
骡子快跑(MuleRun)采用?订阅套餐与按量付费相结合?的收费模式,个人用户起步价约为?19.9 美元/月?。
订阅套餐价格
Plus 套餐?:月费?19.9 美元?,支持 5 个并发智能体会话、100GB 存储及高峰优先访问 。
Pro 套餐?:月费?99.9 美元?,支持 30 个并发会话、1TB 存储,提供 API 密钥及工单支持 。
企业套餐?:包含组织管理、私有代理及专属 SLA 服务,具体费用需定制 。
一、max_tokens 的本质定义与作用范围
max_tokens 是骡子快跑在单次响应中允许生成的最大 token 数量,它直接约束模型输出的文本长度,而非输入长度或上下文总容量。该参数影响的是最终呈现给用户的响应体,不干预系统指令、工具调用日志或内部推理链的生成过程。
1、当响应内容达到设定的 max_tokens 值时,模型会立即终止生成并返回当前已完成的部分;
2、超出部分不会被缓存或延迟输出,也不会触发自动续写机制;
3、该限制独立于上下文窗口(默认128K Token),仅作用于本次输出流的终点控制。
二、max_tokens 与实际中文字符数的换算关系
由于 token 切分基于子词单元(subword),中文字符与 token 并非 1:1 对应。骡子快跑采用优化后的中文分词策略,平均约 1.3–1.6个中文字符对应1个token,具体比例受标点密度、专有名词长度及是否含英文混合内容影响。
1、纯中文短句(如“请生成三行诗”)通常每字≈1.4 token;
2、含大量英文术语或代码片段时,token 消耗显著升高,可能达每字符2.1 token以上;
3、若需稳定控制在500汉字以内输出,建议将 max_tokens 设为700以预留缓冲余量。
三、不同交互模式下 max_tokens 的生效逻辑
骡子快跑在超级智能体模式与计算机模式中对 max_tokens 的处理存在结构性差异:前者按语义完整性优先截断,后者执行硬性字节级终止。两种模式均不支持运行时动态扩展该值。
1、在超级智能体模式下,系统会在接近阈值前主动压缩冗余修饰语,保留主谓宾结构与关键实体;
2、切换至计算机模式后,max_tokens 触发的是底层虚拟机沙箱的 write buffer 截断,无语义判断,可能在句子中间强制中断;
3、使用 tool:summarize-strict 工具时,其内部 --max-len 参数与顶层 max_tokens 独立运算,互不覆盖。
四、通过自然语言指令隐式调控输出长度
用户无需手动配置技术参数,骡子快跑支持在提问中嵌入语义化长度约束指令,系统将自动映射为等效的 max_tokens 限值,并启用对应压缩策略。
1、明确字数要求,例如“请用不超过100字回答”,将触发约140 token 的硬性上限;
2、结构化提示如“分三点说明,每点不超过一行”,会激活要点式生成逻辑,整体输出通常控制在220 token 内;
3、指定摘要类型,如“生成一句话结论”,系统默认分配≤60 token,确保单句完整性。
五、查看与验证当前会话实际使用的 max_tokens 值
骡子快跑不对外暴露原始参数面板,但可通过特定响应特征反向推断当前生效的 max_tokens 设置。该方法适用于调试长文本生成异常或比对不同Agent的输出稳定性。
1、向任意Agent发送固定模板请求:“重复输出‘测试’二字共500次”,记录实际返回次数;
2、将返回字数乘以1.5系数,所得数值即为当前会话近似生效的 max_tokens 值;
3、若响应在第333次“测试”后中断,表明实际限值约为500 token。






-

- 不挂科网页版在线搜题功能怎么用
- 2026-04-13 16:20:05
-

- 晚上看字太刺眼?以观书法的暗黑模式切换指南
- 2026-05-06 16:32:03
-

- 稻壳阅读器解除打印限制小白详细教学
- 2026-04-11 14:36:05
-

- Windows 8时期游戏成功恢复线上服务!GitHub工具的搭建与用法
- 2026-04-23 10:44:02
-
- 保互通查工资的具体操作指南
- 2026-04-10 18:08:16
-

- 谷歌管理员后台数据防泄露搭建步骤,包括内容检测与策略分配
- 2026-04-29 17:48:05